Step by step instructions for submitting 3dsMax jobs with Qube!
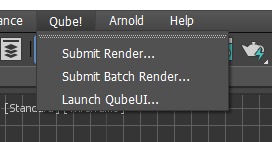
If you have been going through this Install Guide in order, you should be able to locate the "Qube!" menu in 3dsMax (picture). If you don't have that menu item, you need to install the QubeUI 3dsMax In-App Submission UI on the client.
With a scene loaded in 3dsMax choose "Submit Render...".
Note that you could also choose "Submit Batch Render..." depending on your requirements.
This will present a pre-filled submission UI like the one shown at right.
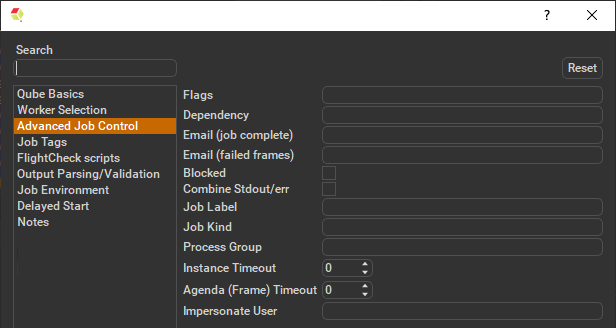
Ensure sections marked in red have the correct details.
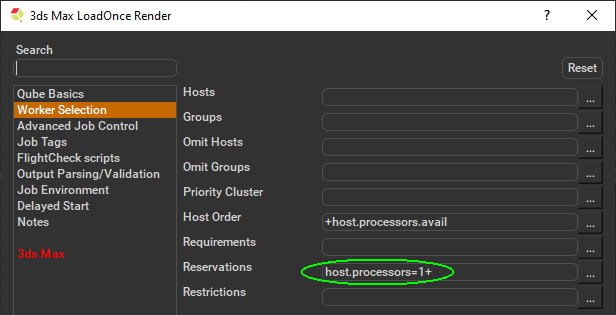
Important: Because 3dsMax doesn't allow thread control, you need to make sure that each instance of 3dsMax occupies the full Worker. By default the "3ds Max LoadOnce Render" submission sets the reservation to "host.processors=1+", but to do this manually select "Worker Selection" and click on the '...' button next to the right. Check the box marked "All" and accept. You should end up with the parameter "host.processors=1+" as shown here.
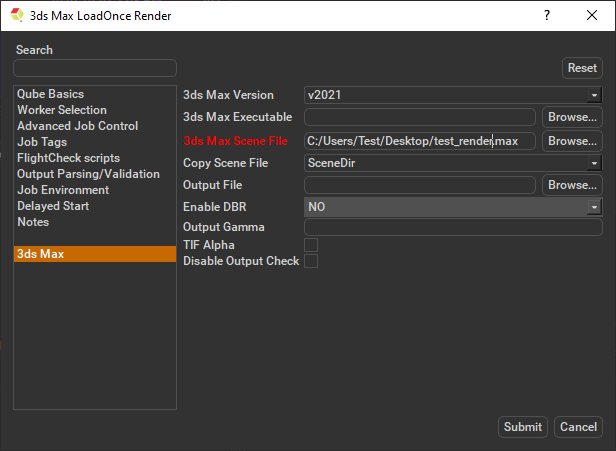
Click 'Submit'
For further details on the submission UI see below.

Job Submission Details
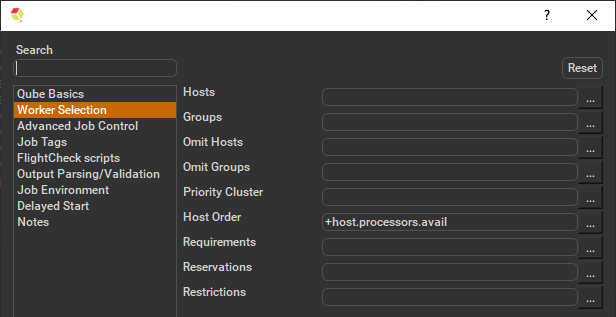
Hosts
Explicit list of Worker hostnames that will be allowed to run the job (comma-separated).
Groups
Explicit list of Worker groups that will be allowed to run the job (comma-separated). Groups identify machines through some attribute they have, eg, a GPU, an amount of memory, a license to run a particular application, etc. Jobs cannot migrate from one group to another. See worker_groups.
Omit Hosts
Explicit list of Worker hostnames that are not allowed run the job (comma-separated).
Omit Groups
Explicit list of Worker groups that are not allowed to run the job (comma-separated).
Priority Cluster
Clusters are non-overlapping sets of machines. Your job will run at the given priority in the given cluster. If that cluster is full, the job can run in a different cluster, but at lower priority. Clustering
 |
|---|
Example:
|
Host Order
Order to select Workers for running the job (comma-separated) [+ means ascending, - means descending].
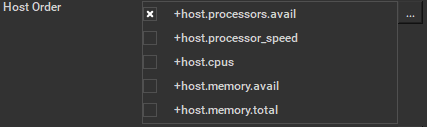 |
|---|
Host Order is a way of telling the job how to select/order workers
|
Requirements
Worker properties needed to be met for job to run on that Worker (comma-separated, expression-based). Click 'Browse' to choose from a list of Host Order Options.
 |
|---|
Requirements is a way to tell the workers that this job needs specific properties to be present in order to run. The drop-down menu allows a choice of OS:
You can also add any other Worker properties via plain text. Some examples:
With integer values, you can use any numerical relationships, e.g. =, <, >, <=, >=. This won't work for string values or floating point values. Multiple requirements can also be combined with AND and OR (the symbols && and || will also work). The 'Only 1 of a "kind" of job' checkbox will restrict a Worker to running only one instance with a matching "kind" field (see below). The prime example is After Effects, which will only allow a single instance of AE on a machine. Using this checkbox and the "Kind" field, you can restrict a Worker to only one running copy of After Effects, while still leaving the Worker's other slots available for other "kinds" of jobs. |
Reservations
Worker resources to reserve when running job (comma-separated, expression-based).
 |
|---|
Reservations is a way to tell the workers that this job will reserve the specific resources for this job. Menu items:
|
Restrictions
Restrict job to run only on specified clusters ("||"-separated) [+ means all below, * means at that level]. Click 'Browse' to choose from a list of Restrictions Options.
 |
|---|
Restrictions is a way to tell the workers that this job can only run on specific clusters. You can choose more than one cluster in the list. Examples:
|
See Also