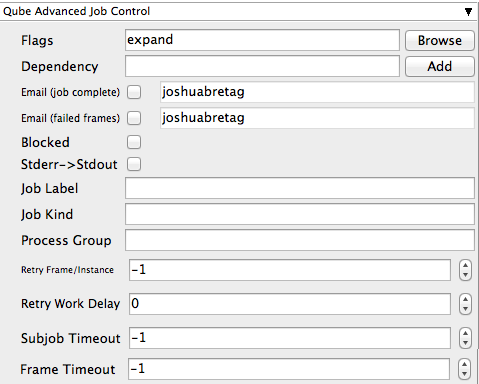
Flags
List of submission flag strings (comma separated). Click 'Browse' to choose required job flags.
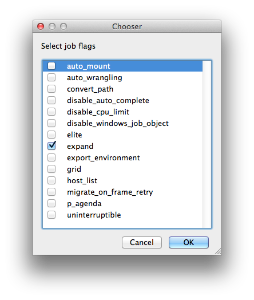
|
|---|
| Value | |
|---|
auto_mount | 8 | Require automatic drive mounts on worker. | auto_wrangling | 16384 | Enable auto-wrangling for this job. | | convert_path | 131072 | Automatically convert paths on worker at runtime. | disable_auto_complete | 8192 | Normally instances are automatically completed by the system when a job runs out of available agenda items. Setting this flag disables that. | disable_cpu_limit | 4096 | Normally, if a job is submitted with the number of instances greater than there are agenda items, Qube! automatically shrinks the number of instances to be equal to the number of agenda items. Setting this flag disables that. | disable_windows_job_object | 2048 | (Deprecated in Qube6.5) Disable Windows' process management mechanism (called the "Job Object") that Qube! normally uses to manage job processes. Some applications already use it internally, and job objects don't nest well within other job objects, causing jobs to crash unexpectedly. | elite | 512 | Submit job as an elite job, which will be started immediately regardless of how busy the farm is. Elite jobs are also protected from preemption. Must be admin. | export_environment | 16 | Use environment variables set in the submission environment, when running the job on the workers. | expand | 32 | (Deprecated in Qube6.5) Automatically expand job to use as many instances as there are agenda items (limited by the total job slots in the farm). | grid | 4 | Wait for all instances to start before beginning work (useful for implementation of parallel jobs, such as satellite renders). | host_list | 256 | Run job on all candidate hosts, as filtered by other options (such as "hosts" or "groups"). | mail | 1024 | Send e-mail when job is done. | migrate_on_frame_retry | 65536 | When an agenda item (frame) fails but is retried automatically because the retrywork option is set, setting this flag causes the instances to be migrated to another worker host, preventing the frame from running on the same host. | | no_defaults | 524288 | Prevent supervisor from applying supervisor_job_flags | p_agenda | 32768 | Enable p-agenda for this job, so that some frames are processed at a higher priority. | uninterruptible | 1 | Prevent job from being preempted. |
|
Dependency
Wait for specified jobs to complete before starting this job (comma-separated). Click 'Add' to create dependent jobs.
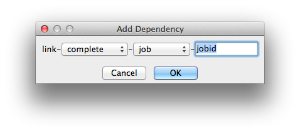 | You can link jobs to each other in several ways: - "complete" means only start this job after designated job completes
- "failed" means only start this job if the designated job fails
- "killed" means only start this job if the job has been killed
- "done" means start this job if the job is killed/failed/complete
|
|---|
Email (job complete)
Send email on job completion (success or failure). Sends mail to the designated user.
Email (failed frames)
Sends mail to the designated user if frames fail.
Blocked
Set initial state of job to "blocked". You would do this if you wanted to set up other jobs for this one to depend on.
Stderr->Stdout
Redirect and consolidate the job stderr stream to the stdout stream. Enable this if you would like to combine your logs into one stream.
Job Label
Optional label to identify the job. Must be unique within a Job Process Group (pgrp). This is a legacy method of labeling jobs. See Job Tags
Job Kind
Arbitrary typing information that can be used to identify the job. It is commonly used to make sure only one of this "kind" of job runs on a worker at the same time by setting the job\'s requirements to include "not (job.kind in host.duty.kind)". See How to restrict a host to only one instance of a given kind of job, but still allow other jobs
Process Group
Job Process Group (pgrp) for logically organizing dependent jobs. Defaults to the jobid. Combination of "label" and "Process Group" (pgrp) must be unique for a job. See Process group labels
Retry Frame/Instance
Number of times to retry a failed frame/job instance. Value of -1 means use the default for the studio. Set this to retry any failed frames or instances automatically.
Retry Work Delay
Number of seconds to wait before automatically retrying a failed frame/work.
Subjob Timeout
Kill the subjob process if running for the specified time (in seconds). Value of -1 means disabled. Use this if the acceptable instance/subjob spawn time is known.
Frame Timeout
Kill the agenda/frame if running for the specified time (in seconds). Value of -1 means disabled. Use this if you know how long frames should take, so that you can automatically kill those running long.