QubeArtistView Preferences Dialog
The preferences are located either under the "Edit" menu (Windows/Linux), or the "qubeArtistView" menu (OS X).
Preferences are split into 3 tabs:
General
- Supervisor override: By default QubeArtistView will query the first supervisor it found when it started up. You can put the name of other, alternate supervisors here and it will display their jobs instead. This is useful for facilities that run multiple Supervisors, perhaps some remotely, and you want to monitor work on those other farms.
- Auto Refresh / Interval: By default the UI must be refreshed manually. You can turn on a timer, and set an interval (in seconds) for it to auto-refresh. Note that refreshing puts load n the supervisor, so caution should be used when enabling this feature, especially at higher frequencies.
- Directly query SQL database: The MySQL user account to query the database. This option should always be enabled unless there is a good reason not to. When in doubt, leave enabled.
- Validate jobs while loading: Check all attributes for each job; this is meant mainly as a troubleshooting aid. EXPENSIVE, use only to troubleshoot when a corrupt job crashes ArtistView. New in 6.9-1
- Job limit (n Jobs): Explicitly limit the number of jobs visible to the user. This is useful in large facilities where there may be many thousands of jobs running. Bringing back information about all of them can be slow, and can also slow down the Supervisor.
- Job limit (n Days): Limit the number of jobs visible to the user based on the number of days since each job was last updated. Jobs are updated any time a worker works on the job or when the job is modified. This is useful in large facilities where there may be many thousands of jobs running. Bringing back information about all of them can be slow, and can also slow down the Supervisor.
- Preview Cache (#items): Preview tabs (and the thumbnails tab when viewing EXR or TGA files) temporarily cache files on the local disk. This sets a limit on the number of images to cache locally. Cache is cleared upon exit.
- Preview exr: Tells the Preview and Thumbnails tabs display exr files. Exr files must be processed before viewing which will require CPU time.
- Apply actions to child jobs: When performing an action on a pgrp leader, i.e. block, modify, kill, retry, etc; the requested action can be performed on all pgrp jobs. The preference determines what is done to the child jobs.
- Display Workers tab: Turns on or off the "Workers" tab on the main layout. It is off by default.
- Display Instances tab: Turns on or off the "Instances" tab on the main layout. It is off by default.
- Display Job Submissions: Selects which job submission types will appear in the submit menu. This is useful for decluttering the UI, since it is unlikely that your installation will be able to submit to all of the applications that Qube! supports.
- Output Path Translation Map: When a worker is running a different OS that the client, the output paths will be relative to the worker OS. This path translation allows one to convert output paths from, say, Windows, to a path that would work on OS X. For example x:\project -> /Volumes/xsan/project.
- Search Method: When performing a search, are we doing a client side filter for matching jobs, or are we doing a server side search for matching jobs? The former is faster; while the latter is more powerful, allowing you to search any field in the job, i.e.
name:Maya AND reservations:"host.processors=1+".

Submission
Submission preferences dictate which submission UIs will be visible in the "Submit" pulldown menu.
- If "ALL" is selected, all available submission UIs will be visible, regardless of any other selections.
- Adding custom submission scripts can be done by including their containing directory at the bottom of this dialog.

Plugins
- The plugins tab is separated into two sections: Menu plugins and Tab plugins.
- Menu plugins are those that drive the right-click menu system. Tab plugins are those that drive the lower tabs and their contents.
- With "Loaded" disabled, the plugin will not be loaded or displayed.
- Adding custom plugins is discussed in detail on the Adding Custom Plugins page.

Columns
Manipulating Columns
The columns tab allows you to add, remove, arrange, and customize columns displayed in the GUI. It has sub-tabs for each of the main lists in the GUI - Jobs, Instances, Frames, and Hosts/Workers.
In each tab, you will see a list of available attributes for that entity and a list of "In Use" attributes that are currently being displayed.
- To add a column, simply drag it from the "Available" list to the "In Use" list.
- To remove a column, drag it from "In Use" to "Available".
- To reorder the columns, drag them within the "In Use" list.
Columns can be customized by changing the column display name, the attribute or function used to get the attribute, and/or the display formatting for data in that column. To edit display properties, double click the attribute name to expose and edit dialog with the following:
- Display Name: The column name as it will appear in the interface. Unicode characters are allowed. For most attributes, this is the only field that is required.
- Attribute: The key or method used to get the data from its python object. If no attribute is supplied, the display name will be used. There are a few ways to get the information using the attribute field:
- For top-level job attribute like job id and job name, simply use the attribute name. For example, to get a job's id, you use the attribute "id" - this will get
object['id']. To get the job's owner, you would use the attribute "user" - this will getobject['user'] - To get a nested attribute, use the colon (':'), e.g. an attribute of "package:custom_variable" would get
object['package']['custom_variable'] - If there is a function associated with the python object, you can enter the function call with parenthesis, though parameters are not allowed. For example "getProgress()" will call the
object.getProgress()function. - Nesting and function calls can be used together, e.g. "customFunction():custom_param:x" would get
custom_function()['custom_param']['x']
- For top-level job attribute like job id and job name, simply use the attribute name. For example, to get a job's id, you use the attribute "id" - this will get
- Format: How to display the data using standard printf notation. If left blank, %s is assumed (any objects that are returned by the calling function/attribute will be serialized and displayed)
- Name: Optional, internal only parameter, used to keep track of attribute mappings.
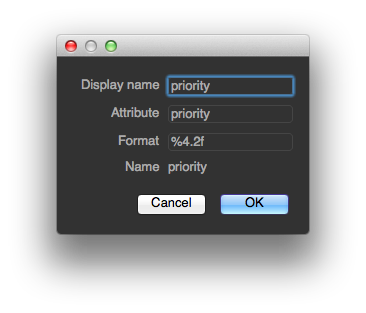
You can even do this with the native Qube! column data. For example, you could display the job priority as floating point if you wanted, by double-clicking on the "priority" entry and filling out the details as shown.

Adding Custom Column Data
In this tab of the preferences dialog, you can edit the columns to display your own, custom data. Here is how.
Let's assume your facility has written custom data to a frame's (aka "work item", aka "agenda item") resultpackage, using the key 'customData'. From the API, you would access this data like so:
How to populate that data is beyond the scope of this document. Feel free to write into support@pipelinefx.com for more information on that.
Assuming data exists, you can display this data in ArtistView by customizing a column through the preferences. You can also use custom Tags for this information - see the page on Tags.
To add a columns for 'customData' in ArtistView:
- Go to the "Columns" preferences and look at "Frames":

Drag any item from the left column to the right column. For this example, we'll use "subid", but it doesn't matter what you choose - it's just a placeholder. In fact, because you're re-naming the placeholder, subid will be an option to add the next time you want to add it. In other words, you can do this as many times as you'd like without using up all of the standard attributes.
Once you drag it over to the right column (in the correct order where you want it displayed), double-click it. This will bring up the edit dialog:

- Change "Display name" to whatever you would like to be displayed in the column header. This can be any ascii or unicode string.
- For this example, we will use "Custom data"
- Next, we need to set "Attribute".
- The attribute is any attribute of the agenda/work item as it can be seen from the API.
- Example:
work['macaddress']would use the attribute'macaddress'
- Example:
- If the attribute you need is in a dictionary (as the one in this example), you can access dictionary items using the colon
- Example:
work['resultPackage']['outputPaths']would use the attribute'resultPackage:outputPaths' - Example:
work['foo']['bar']['gah']would use the attribute'foo:bar:gah'
- Example:
- For this example, we will use
'resultPackage:customData', as we are accessingwork['resultPackage']['customData']
- The attribute is any attribute of the agenda/work item as it can be seen from the API.
- Optional: If the custom data could benefit from formatting, you can do so in the "Format" section, i.e. %3.2f. If you leave it blank, it will pass straight through (equivalent to %s).
- The customized column dialog should look like:

When all is said and done, you will then have a custom column in ArtistView displaying your own custom data:
